python 시각화: Seaborn 패키지(1)
python을 공부하는 초반이라, 탐색적 분석에 필요한 시각화 방법들을 익히고 있다. seaborn은 EDA를 효율적으로 할 수 있다는 점에서 무척 매력적인 패키지다. 그래서 처음으로 공식 문서를 샅샅이 읽어보며 정리해본다.
참조 : https://seaborn.pydata.org/introduction.html
왜 만들어졌나?
- 데이터를 탐색하고 이해하는 과정에서 visualization이 핵심 역할을 하게끔 하려고
특징
- 여러 변수 간의 관계를 탐색하는 데에 좋다.
- 특히 범주형 변수를 이용해 분포를 살펴보거나 집계하는 작업을 잘 지원한다.
- 데이터의 subset 간에 단일 변수 또는 2개 변수의 분포를 서로 비교하기 쉽다.
- 빌트인된 테마를 이용해 matplotlib의 스타일링 요소들을 간단히 컨트롤할 수 있다.
- 분석하고자 하는 내용에 따라 크게
relplot()(relation),catplot()(category)를 제공한다.
주요 argument
hue,style- 범주형 변수를 3번째 축으로 이용해 subset별로 살펴볼 때 상요
- 각각 컬러/도형으로 반영
ci- relplot()은 신뢰구간(confidence interval)을 함께 보여줌
- 데이터셋이 커서 계산 시간이 길어지면
ci=None으로 비활성화
1. 연속형 변수 x 연속형 변수
seaborn은 변수 간의 관계를 분석하기 위한 함수들을 relplot()으로 묶어서 제공하고 있다.
relplot()
- 지원하는 plot의 종류 : scatter plot과 line plot
- scatter plot : 디폴트로 되어 있음
- line plot :
kind='line'
1) Scatter plot
- 산점도
- 두 변수 간의 관계를 시각화한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
tips = sns.load_dataset('tips')
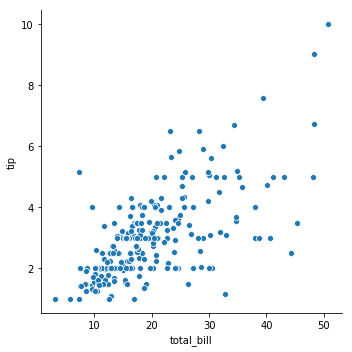
# 결제금액과 팁 사이에 상관관계가 있는가?
sns.relplot(x='total_bill', y='tip', data=tips)
plt.show()
2) Linear regression
regplot(): scatter plot과 회귀선, 신뢰구간을 함께 그려줌hue,col,row를 지원하지 않음- 회귀선만 그리고 싶다면
scatter=None으로 설정
lmplot(): regplot()과 FacetGrid를 결합한 것hue,col,row를 지원함
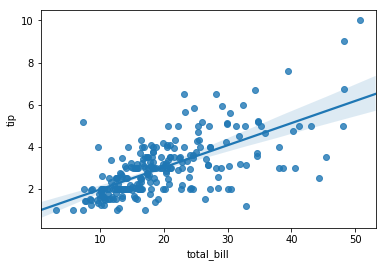
sns.regplot(x='total_bill', y='tip', data=tips)
plt.show()
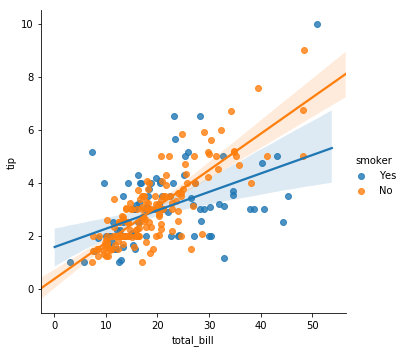
# 결제금액과 팁 간의 상관관계가 흡연자/비흡연자별로 차이가 있는가?
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)
plt.show()
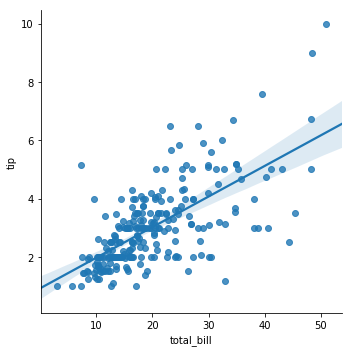
sns.lmplot(x="total_bill", y="tip", data=tips)
plt.show()
3) Line plot
- 시간축에 따른 변화의 추이를 살펴볼 때 사용
relplot()에서kind='line'으로 설정- 또는
lineplot()
fmri = sns.load_dataset("fmri")
sns.relplot(x='timepoint', y='signal', kind='line', data=fmri, hue='event', style='event', ci=None)
plt.show()
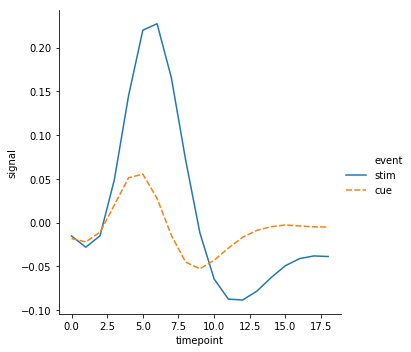
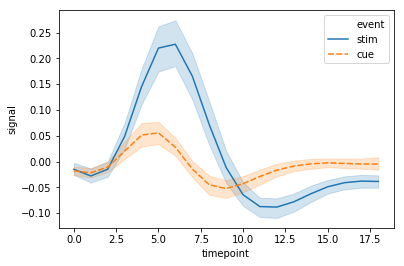
# lineplot()
fmri = sns.load_dataset("fmri")
sns.lineplot(x='timepoint', y='signal', data=fmri, hue='event', style='event')
plt.show()
2. 범주형 변수 x 연속형 변수
범주형 변수를 기준으로 category별 subset 간의 경향을 비교하려면 catplot()을 사용한다. 문서에서는 이를 ‘범주형 plot을 FacetGrid에 그리기 위한 Figure-level interface’라고 설명하고 있다.
R에 비해 굉장히 효율적이라고 느껴지는 부분이다. 세부적인 설정도 default로 셋팅해둬 작업이 많이 자동화된다.
- 한 개 이상의 범주형 변수를
- plot과 FacetGrid를 리턴한다.
다음과 같은 axes-level function을 지원한다.
scatter plot
- stripplot() (kind=”strip”, 디폴트)
- swarmplot() (kind=”swarm”)
분산을 볼 수 있는 plot
- boxplot() (kind=”box”)
- violinplot() (kind=”violin”)
- boxenplot() (kind=”boxen”)
Estimate plot
- barplot() (with kind=”bar”)
- countplot() (with kind=”count”)
- pointplot() (with kind=”point”)
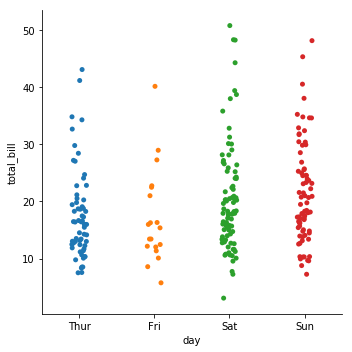
1) catplot(kind=strip)
- jitter가 디폴트로 적용되어 있다.
- 비활성화 :
jitter=False
# 평일/주말에 따라 결제액이 다른가?
sns.catplot('day','total_bill', data=tips)
plt.show()
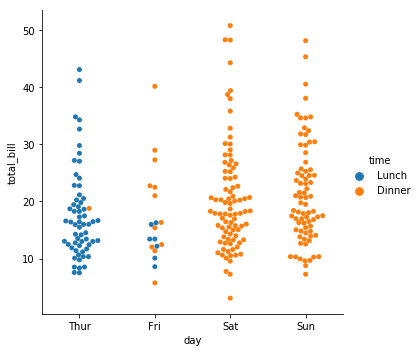
2) swarmplot()
- 값들이 서로 overlapping되지 않도록 알고리즘을 적용한다.
- 모든 값이 겹치지 않고 펼쳐지므로 추가적인 변수를 적용해 분석하기 좋다.
sns.catplot('day','total_bill', hue='time', kind='swarm', data=tips)
plt.show()
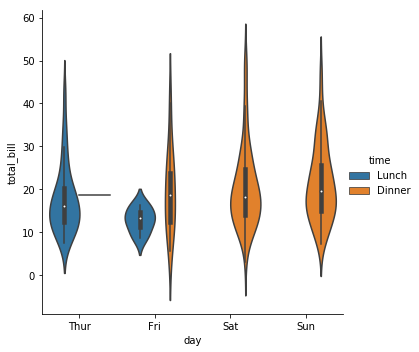
3) violinplot()
- swarmplot에
hue를 적용한 경우, 두 그룹이 섞여서 표현될 수 있다. violinplot은 이 둘을 분리해서 표시한다.
sns.catplot('day','total_bill', hue='time', kind='violin', data=tips)
plt.show()
3. 어떤 함수를 쓸 것인가?
relplot() vs. violinplot()
- lineplot(), violinplot() 등 axes-level 함수를 사용하는 것보다 catplot(), relplot() 등 Figure-level interface의 스타일 셋팅이 다름
- 범례의 스타일 및 위치, x축의 높이, 범례/plot 영역 테두리 등
- 가독성과 심미성을 위해 relplot(), catplot()에
kindargument를 사용하는 게 좋을 듯
# Figure-level Interface
sns.violinplot('day','total_bill', hue='time', data=tips)
plt.show()
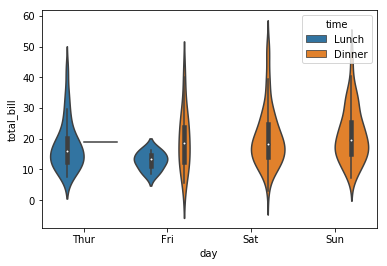
# Axis-level Function
sns.catplot('day','total_bill', hue='time', kind='violin', data=tips)
plt.show()
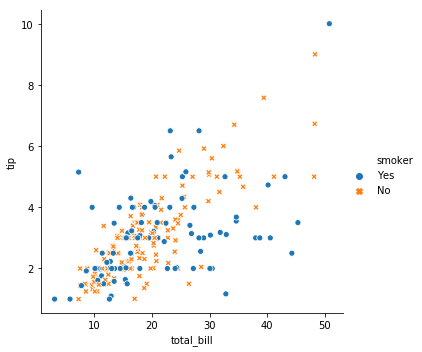
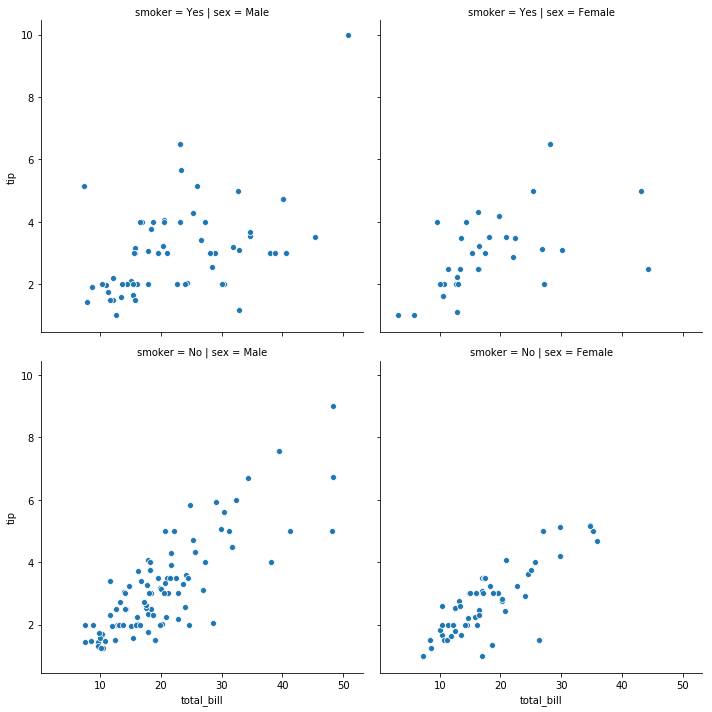
4. Facet Grid
- 그룹 간 비교
- 데이터의 subset별로 선형회귀를 적용한다. (by applying a groupby operation)
hue,style: 범주형 변수 지정pallette: 그룹별 컬러링할 컬러 팔레트 설정
sns.relplot('total_bill', 'tip', hue='smoker', style='smoker', data=tips)
plt.show()
- subplot들을 Grid로 그려서 비교
row: n개의 row로 배치col: n개의 column으로 배치- 둘 다 적용하면 n x n grid가 됨
sns.relplot('total_bill', 'tip', data=tips, col='sex', row='smoker')
Subscribe via RSS