python 시각화: Stacked Bar Chart 그리기
python을 빠르게 익히기 위해 DS스쿨의 실전 데이터분석가 과정을 1월에 수강했었다.
이 코스를 선택한 가장 큰 이유는 수업에서 제공하는 몇몇 스타트업의 로그데이터와(많이 정제된 버전이지만) 이후의 채용연계 과정이 궁금해서였다. 마지막 4주차 강의가 끝날 때 특정 스타트업에서 제공한 과제를 풀고 있는데, 누적 막대 그래프를 그려야 할 일이 생겼다. 이론적으로 너무 간단한 일이지만 의외로 헤맸던 부분이 있어서 기록으로 남겨본다.
결론
- Matplotlib의 stacked=True 옵션을 사용하는 게 가장 간단하다.
- 데이터가 복수의 array 형태라면, 레이어를 쌓는다는 개념으로 차곡차곡 포갠다.
- 또는 bar segment의 시작 지점을 지정할 수 있다. 하지만 이 방법은 잘 안먹힐 때가 있다.
- Seaborn으로는 간단하게 그릴 수 없다. 이 패키지를 만든 사람이 누적 막대 그래프 자체를 싫어하더라.
1. pandas plot의 stacked 옵션 사용
-
아래와 같은 데이터가 있다고 해보자. x축에 Year, y축에 value를 보여주는 bar chart를 그리되, 월별로 bar segment를 stack해서 보려는 상황이다.
import pandas as pd
data = [[2000, 2000, 2000, 2001, 2001, 2001, 2002, 2002, 2002],
['Jan', 'Feb', 'Mar', 'Jan', 'Feb', 'Mar', 'Jan', 'Feb', 'Mar'],
[1, 2, 3, 4, 5, 6, 7, 8, 9]]
rows = zip(data[0], data[1], data[2])
headers = ['Year', 'Month', 'Value']
df = pd.DataFrame(list(rows), columns=headers)
df
데이터를 피봇해준다.
# 테이블 피벗하기
pivot_df = df.pivot(index='Year', columns='Month', values='Value')
pivot_df = pivot_df[['Jan','Feb','Mar']].copy()
pivot_df
[['Jan','Feb','Mar']] 부분은 월별로 순서를 정렬하게 위해 적용했다.
import matplotlib.pyplot as plt
%matplotlib inline
# Stacked Bar Chart
pivot_df.plot.bar(stacked=True, figsize=(10,7))
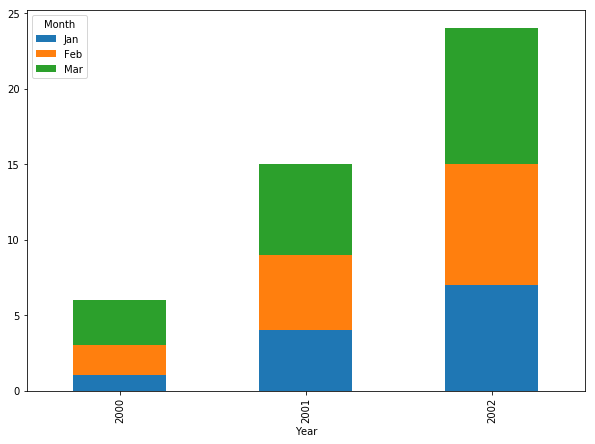
그렇데 이렇게만 그리면 문제가 있다. 가독성 측면에서 legend와 bar segment의 순서가 반대로 표시되는 것이다. 이렇게 그려지는 이유는 다음과 같다.
- legend는 top-to-botton 순서로 뿌려진다.
- 차트를 그리는 과정에서 stacking은 x축과 y축이 교차하는 지점에서부터 botton-to-top으로 이루어진다.
만드는 논리상으로는 문제가 없는 결과지만, 데이터 시각화의 결과물이 철저히 사용자 중심으로 만들어져야 한다는 측면에선 틀렸다. 이 문제를 논의한 기록을 우연히 발견했는데, 일종의 작은 컬처쇼크라고 해야할지 서로의 입장차이가 참 재밌었다.
참고 링크
- 이슈제기 : Bar segments are sorted in opposite order of legend.
- 적용 : ENH: allow legend=’reverse’ in df.plot() GH6014
해결방법 : legend의 순서를 Bar segment와 일치시키기 위해 legend='reverse'를 추가해준다.
pivot_df.plot.bar(stacked=True, legend='reverse', figsize=(10,7))
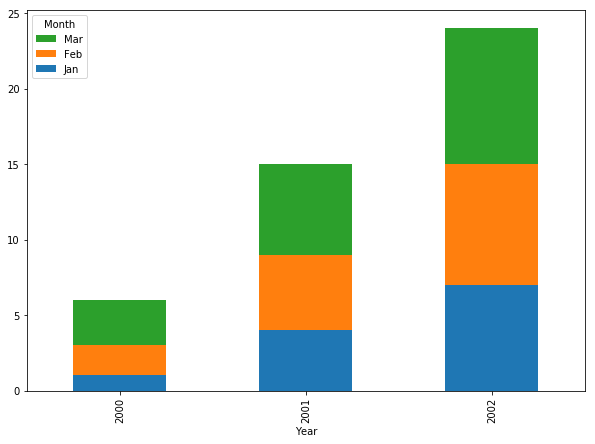
시각화의 내용물을 직관적으로 파악할 수 있게 범례의 순서가 바뀌었다. 위의 내용을 R로 구현하면 아래와 같다.
library(ggplot2)
year = c(2000, 2000, 2000, 2001, 2001, 2001, 2002, 2002, 2002)
month = c('Jan', 'Feb', 'Mar', 'Jan', 'Feb', 'Mar', 'Jan', 'Feb', 'Mar')
value = c(1, 2, 3, 4, 5, 6, 7, 8, 9)
df = data.frame(year, month, value)
df$year <- as.factor(df$year)
ggplot(df, aes(x=year, y=value, fill=month)) + geom_bar(stat='identity', width=0.5)
2. Matplotlib를 이용해 수동으로 레이어 쌓기
다음은 다소 원시적인 방법이다. 그런데 ‘python stacked bar chart’로 구글링했을 때 의외로 이런 방법들이 많이 검색된다. 심지어 matplotlib.org 공식 사이트에서도 이 방법을 제시하고 있으니, 정말 이렇게 해야하나보다 생각할 수밖에 없었다.
참고링크 : Stacked Bar Graph (matplotlib.org)
import numpy as np
import matplotlib.pyplot as plt
# 데이터셋 준비
N = 5
ind = np.arange(N)
upper = (20, 25, 30, 32, 35)
bottom = (20, 21, 20, 21, 20)
# bottom을 지정해 위로 쌓는 방법
p1 = plt.bar(ind, bottom)
p2 = plt.bar(ind, upper,
bottom=bottom)
plt.legend((p2[0], p1[0]), ('Upper', 'Bottom'))
plt.xticks(ind, ('G1', 'G2', 'G3', 'G4', 'G5'))
plt.show()
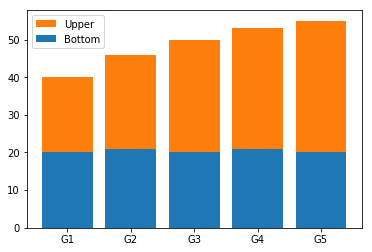
역시 legend와 bar segment의 순서를 일치시켜 가독성을 높이기 위해, 순서상 나중에 그려준 Upper를 legend에선 앞쪽에 위치시켰다.
이 방법의 문제는, 예시에서는 잘 구현되지만 다른 데이터셋으로 그렸을 때 제대로 작동하지 않았다는 점이다. 중간에 공백이 생기는 등 bottom 라인이 지정한 대로 작동하지 않는 것으로 보인다. 이 문제는 정확한 원인과 주의점을 알게 되면 이 문서에 업데이트하려고 한다.
3. Seaborn을 이용하는 방법
아쉽게도 seaborn을 이용해 심플하고 우아하게 stacked bar chart를 그리는 방법은 찾아내지 못했다. 하지만 누군가 이 문제로 고심하다가 올린 글을 보았는데, 아마 그런 방법은 현재 없고 앞으로도 업데이트되기 어려울 것으로 보인다. 이 글에 의하면 seaborn 패키지를 만든 당사자가 이런 차트 자체를 싫어한다고 한다.
@randyzwitch I don’t really like stacked bar charts, I’d suggest maybe using pointplot / factorplot with kind=point
참고 링크 : Creating A Stacked Bar Chart in Seaborn
이 글을 쓴 사람이 찾아낸 방법은 bar를 2개 겹쳐그리는 것이다. 다른 글에서도 대부분 함수를 만들어 비슷하게 해결하는 것으로 보였다.
느낀 점
- 누적 그래프는 segment의 개수가 많아지면 추이를 비교하기 힘들고 가독성이 떨어지는 건 사실이다. 하지만 대시보드 등에 꼭 필요한 경우가 있으니 가장 간편한 방법으로 익혀두면 좋을 듯하다.
- 이렇게 조금이라도 시각화 방식이 복잡해지면, 데이터셋이 어떤 식으로 정리되어 있어야 하는지 헷갈리기 쉽다. 원하는 테이블로 빨리빨리 변환할 수 있게 pivot, stack 등을 잘 익혀둬야겠다.
Subscribe via RSS