[번역] 데이터 분석을 위한 SQL 쿼리 효율
SQL을 독학으로 공부하다 보니, 쿼리가 복잡해지면 효율적인 쿼리를 짜고 있는 건지 의문이 들 때가 있다. 최근 해커랭크의 SQL 챌린지를 정주행했는데 특히 3~4개 이상의 테이블을 JOIN하거나 서브쿼리가 복잡해지면 그런 경우가 많았다. 그래서 이제는 스스로 애매하게 느껴지는 부분은 구글링해서 공부하며 병행해보려 한다.
아래 내용은 Mode Analytics 웹사이트의 SQL 튜토리얼 중 쿼리 효율에 관한 챕터를 번역한 것이다. https://community.modeanalytics.com/sql/tutorial/sql-performance-tuning/
서브쿼리에 관한 앞의 챕터에서는 실행시간이 보다 빠른 쿼리로도 같은 결과를 얻을 수 있다는 개념을 소개한 바 있다.
이번 수업에서는 어떤 경우에 쿼리를 개선할 수 있고, 어떻게 해야 하는지를 다룰 것이다.
쿼리 실행시간에 관한 배경지식
데이터베이스는 컴퓨터에서 실행되기 위한 소프트웨어의 일부다. 그러므로 소프트웨어와 똑같은 한계가 있다. 하드웨어가 핸들링할 수 있을 정도의 정보만을 프로세스할 수 있는 것이다. 더 빠르게 실행되는 쿼리를 짜려면 소프트웨어와 하드웨어가 수행해야 하는 계산의 수를 줄여야 한다. 그러려면 SQL이 실제로 어떻게 계산을 하는지를 이해할 필요가 있다. 먼저 계산의 수와 쿼리 실행시간에 영향을 미치는 몇 가지 중요 요소를 살펴보자.
- 테이블 크기 : 쿼리가 건드리는 테이블이 수백만 row 이상이라면 성능에 영향을 미친다.
- JOIN : 결과셋의 row 수가 상당히 증가하는 방식으로 두 개의 테이블을 JOIN한다면 쿼리는 느려질 것이다. 이에 관한 예시가 서브쿼리 강의에 있다.
- 집계(aggregations) : 여러 개의 row를 결합해 결과를 산출하려면 단순히 검색할 때보다 계산량이 더 많다.
쿼리 실행시간은 당신이 컨트롤할 수 없는, DB 자체에 관한 것들과도 관련이 있다.
- 쿼리를 실행하고 있는 다른 유저들 : 더 많은 쿼리가 동시에 실행될수록 DB는 같은 시간에 더 많은 양을 처리해야 하고, 실행되는 모든 것들이 느려진다. 다른 사람이 특히 위에 언급되었던 자원 집중적인 쿼리를 실행하고 있다면 상황은 더 나빠진다.
- DB 소프트웨어와 최적화 : 이건 아마 당신이 컨트롤할 수 없는 부분일 것이다. 하지만 어떤 시스템을 사용하고 있는지 알고 있으면 가능한 범위 내에서 쿼리를 더 효율적으로 짤 수 있다.
자, 이제부터 당신이 컨트롤할 수 없는 일은 무시하고 할 수 있는 부분에 집중해 보자.
테이블 크기 줄이기
필요한 관측치(observation)만 포함되도록 데이터를 필터링하면 쿼리 실행속도를 드라마틱하게 개선할 수 있다. 구체적인 방법은 당신이 어떤 문제를 해결하려 하는지에 따라 전적으로 달라진다. 예를 들어 시계열 데이터를 다루고 있다면 작은 시간범위로 제한하면 쿼리를 보다 빠르게 실행할 수 있다.
SELECT *
FROM ben.sample_event_table
WHERE event_date >= ‘2014-03-01’
AND event_date < ‘2014-04-01'
이런 작업 방식을 꼭 기억해 두길 바란다. 1) 데이터의 일부분(subset of data)에 대해 탐색적 분석을 하고, 2) 더 정교하게 다듬어서 최종 쿼리로 만든 뒤, 3) 제한값을 제거해 전체 데이터셋에 실행하는 것이다. 최종적인 쿼리는 여전히 실행에 꽤 오랜 시간이 걸리겠지만 최소한 중간 과정만큼은 시간을 단축시킬 수 있다.
바로 그런 이유 때문에 Mode는 LIMIT 절을 디폴트로 두고 있다. 100 row의 데이터셋은 다음 단계의 분석 방향을 결정하기엔 충분하면서, 쿼리를 빠르게 실행해보기에 적당한 크기다.
다만 알아둘 점은, LIMIT는 집계와 함께 작동하지 않는다는 점이다. 먼저 집계가 이루어진 뒤 결과의 row 갯수가 특정 값으로 제한될 뿐이다.
그러므로 만약 아래와 같이 하나의 값만 집계하는 경우라면 LIMIT 100은 쿼리 속도에 아무 영향도 미치지 못한다.
SELECT COUNT(*)
FROM ben.sample_event_table
LIMIT 100
만약 속도를 올리기 위해 COUNT하기 전에 데이터셋을 제한하고 싶다면, 서브쿼리 내에서 해야 한다.
SELECT COUNT(*)
FROM (
SELECT *
FROM ben.sample_event_table
LIMIT 100)
) sub
주의할 점 : LIMIT를 쓰면 결과가 극적으로 달라진다. 따라서 쿼리 로직을 테스트할 때만 쓰고, 실제 결과를 얻을 때는 사용하지 말아야 한다.
일반적으로 서브쿼리를 쓸 때는, 가장 먼저 수행되는 곳에 LIMIT를 써서 당신이 다루는 데이터의 양을 제한해야 한다.
즉, LIMIT를 메인쿼리가 아닌 서브쿼리 내에 써야 한다는 뜻이다. 다시 말하지만 이것은 테스트하는 쿼리의 속도를 높이기 위한 것이다.
더 나은 결과를 얻기 위한 것이 아니다.
덜 복잡하게 JOIN하기 (Making joins less complicated)
앞선 팁의 연장선상에 있는 내용이다. 쿼리 내의 먼저 수행되는 지점에서 데이터의 양을 줄이는 것이 좋은 것과 마찬가지로, 테이블을 조인하기 전에 사이즈를 줄이는 것이 좋다. 아래 예시는 여러 대학의 운동선수 리스트에 각 대학 운동팀에 관한 정보를 조인하는 것이다.
SELECT teams.conference AS conference,
players.shcool_name,
COUNT(1) AS players
FROM ben.college_football_players players
JOIN ben.college_football_teams teams
ON teams.school_me = players.school_name
GROUP BY 1,2
ben.college_football_players 테이블은 26,298행으로 되어 있다. 이것은 다른 테이블과 매치할 때 26,298행이 계산되어야 한다는 뜻이다.
하지만 ben.college_football_players 테이블을 미리 집계하면, JOIN할 때 계산해야 할 행의 갯수를 줄일 수 있다. 먼저 집계를 해보자.
SELECT players.school_name,
COUNT(*) AS players
FROM ben.college_football_players players
GROUP BY 1
위의 쿼리는 252개의 결과를 반환한다. 따라서 이것을 서브쿼리 안에 넣고 메인쿼리에서 조인을 실행하면 비용을 상당히 줄일 수 있다.
SELECT teams.conference,
sub.*
FROM (
SELECT players.school_name,
COUNT(*) AS players
FROM benn.college_football_players players
GROUP BY 1
) sub
JOIN benn.college_football_teams teams
ON teams.school_name = sub.school_name
이런 예시에서는 큰 차이가 느껴지지 않을 것이다. 30,000행은 데이터베이스가 계산하기 힘든 양이 아니기 때문이다.
하지만 수십만 행 이상이 되면 JOIN하기 전에 집계함으로써 성능이 확 개선될 것이다. 다만 주의할 점은 당신이 하는 일이 논리적으로 일관성 있는지를 체크해야 한다.
실행속도보다는 작업의 정확도가 우선이다.
EXPLAIN
어떤 쿼리든 시작 부분에 EXPLAIN을 써서 실행시간이 얼마나 오래 걸릴지 감을 잡을 수 있다. 정확도가 완벽한 건 아니지만, 어쨌든 유용한 툴이다. 아래 예시를 보자.
EXPLAIN
SELECT *
FROM benn.sample_event_table
WHERE event_date >= '2014-03-01'
AND event_date < '2014-04-01'
LIMIT 100
아래와 같은 결과가 나올 것이다.
이를 쿼리 플랜(query plan)이라고 한다. 쿼리가 어떤 순서로 수행될 것인지를 보여주는 것이다.
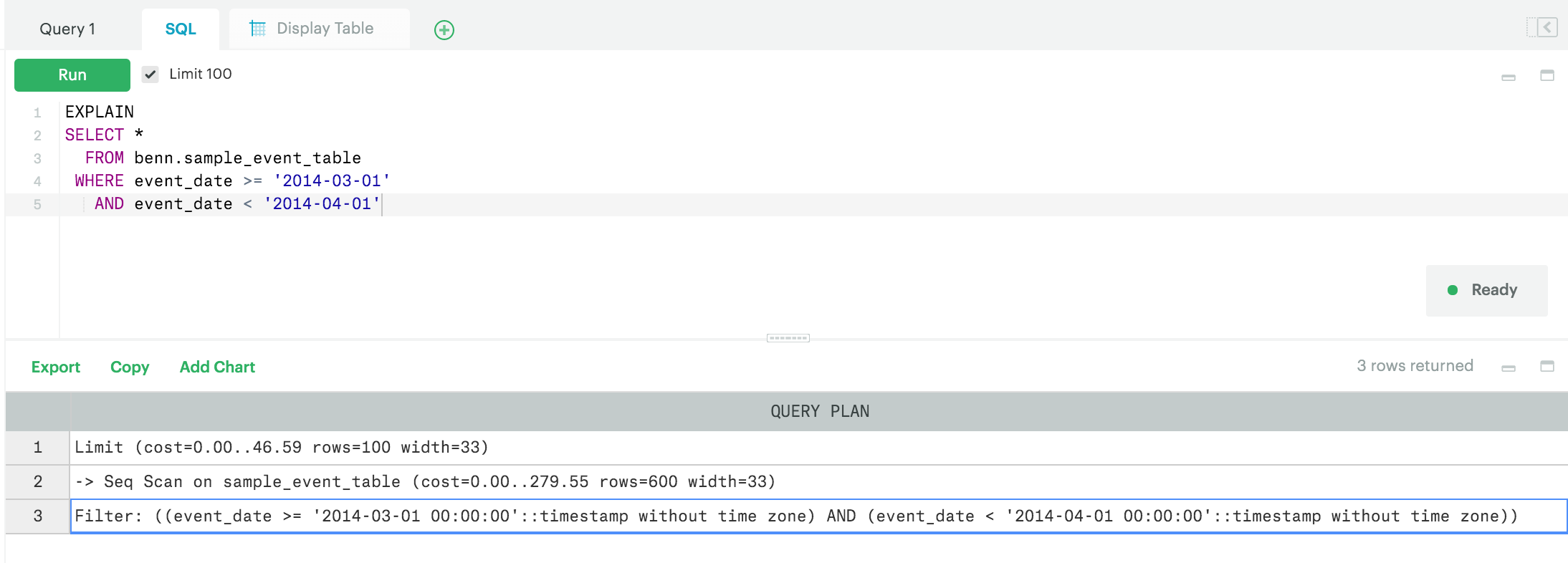
목록의 가장 밑에 있는 entry가 먼저 실행된다. 따라서 데이터의 범위를 제한하는 WHERE절이 먼저 실행될 것임을 보여준다.
그리고 나면 데이터베이스는 600여개의 행을 스캔한다. 행의 개수 옆에 표기된 수행비용이 보일 것이다. 숫자가 클수록 실행시간이 오래 걸린다.
이 숫자는 절대적인 측정값이라기 보다는 참고사항으로 활용해야 한다.
가장 유용한 방식을 명확히 하자면, 쿼리에 EXPLAIN을 해보고, 가장 비용이 높은 부분을 수정한 뒤, 비용이 줄었는지 확인하기 위해 EXPLAIN을 다시 해보는 것이다.
마지막으로 LIMIT 절은 가장 마지막에 실행되며 비용이 가장 낮다. (LIMIT는 24.65 vs. WHERE은 147.87)
Subscribe via RSS