Kiwi 형태소분석기를 사용해보자.
Motivation
Konlpy 패키지의 형태소분석기들을 비교하느라 검색을 거듭할수록 텍스트 분야에 내공이 깊은 분들의 블로그를 발견하게 되었다. 그 중에 2009년경 ‘재미삼아 형태소분석기를 만들어보았다’는 글이 인상깊어서 나중에 다시 찾아보게 되었는데, 도대체 형태소분석기는 어떤 원리로 동작하는 거고 어떻게 만드는 거야? 하는 궁금증이 생겼기 때문이다. 이 분의 블로그를 덕질해본 결과 이 형태소분석기에는 Kiwi라는 이름이 붙었고, 지금도 꾸준하게 업데이트되고 있다는 사실을 알게 되었다.
WHAT | Kiwi 형태소분석기란?
C++로 만들어져 Konlpy와 JDK를 설치할 때 같은 어려움 없이 정말 초간단하게 설치해서 사용해볼 수 있는 국문 형태소분석기이다. 공식 문서에서도 다음과 같이 특징을 설명하고 있다. (https://lab.bab2min.pe.kr/kiwi)
- 외부 라이브러리 의존 없이 순수 C++로만 작성되어 어떤 환경에서도 사용할 수 있습니다.
- 사용자가 필요에 따라 사전 내용을 추가할 수 있습니다.
설치 과정은 아래 한 줄이 끝이다.
pip install kiwipiepy
WHY | 왜 Kiwi를 공부해보고 싶어졌나?
지속적으로 관리되고 기능이 개선되는 형태소분석기를 사용하고 싶었다.
Konlpy를 통해 사용해본 형태소분석기들은 깃허브를 보면 거의 최근에 업데이트가 없는 것처럼 보였다.
이런 부분들은 아래 공식 페이지를 통해 확인할 수 있다. 형태소분석기마다 차이는 있지만 약 최근 2년간은 업데이트되지 않은 형태소분석기들이 많았다.
-
Mecab : https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
-
Okt (구. Twitter) : https://github.com/open-korean-text/open-korean-text/
-
Komoran
- 깃허브 : https://github.com/shineware/KOMORAN
- 공식 문서 : https://docs.komoran.kr/
- 샤인웨어 홈페이지 : https://www.shineware.co.kr/products/komoran/
반면 Kiwi는 꾸준히 관리가 되고 있었다. 개발자 분이 리포팅된 이슈를 정말 성심성의껏 관리하고 하나씩 해결해나가고, 기능도 지속적으로 개선되고 있었다. 그래서 구글링을 해보니 이 형태소분석기를 만드신 개발자 님이 카카오 엔터프라이즈에서 관련 업무를 하고 계신 ‘실무자’이셨다. 아, 이건 써봐야 한다, 쓰면서 깊이 배워야겠단 생각이 들었다.
HOW | Kiwi 형태소분석기 사용 방법
Konlpy를 통해 Mecab, Okt, Komoran을 사용하다 보면 아래와 같은 간결한 사용법과 결과에 익숙해지게 된다.
from konlpy.tag import Okt
okt = Okt()
text = "카카오워크를 효과적으로 사용하려면"
# 품사 태깅
okt.pos(text)
> [('카카오', 'Noun'),
('워', 'Noun'),
('크를', 'Verb'),
('효과', 'Noun'),
('적', 'Suffix'),
('으로', 'Josa'),
('사용', 'Noun'),
('하려면', 'Verb')]
# 명사만 추출하기
okt.nouns(text)
> ['카카오', '워', '효과', '사용']
그런데 Kiwi는 기본적인 토크나이징을 하면 아래와 같은 결과를 돌려준다.
from kiwipiepy import Kiwi
kiwi = Kiwi()
kiwi.tokenize(text)
# 결과
[Token(form='카카오', tag='NNP', start=0, len=3),
Token(form='워크', tag='NNG', start=3, len=2),
Token(form='를', tag='JKO', start=5, len=1),
Token(form='효과', tag='NNG', start=7, len=2),
Token(form='적', tag='XSN', start=9, len=1),
Token(form='으로', tag='JKB', start=10, len=2),
Token(form='사용', tag='NNG', start=13, len=2),
Token(form='하', tag='XSV', start=15, len=1),
Token(form='려면', tag='EC', start=16, len=2)]
일단 복잡해보였다. 파이썬 중급자/고급자를 위한 기능들인 것 같아 어떻게 가공해야 할지 감이 오지 않았다. 내용을 살펴보면 순서대로 토큰, 품사태그, 문서 내에서의 위치, 토큰 길이를 제공하고 있다. 필요와 목적에 맞게 고도로 커스터마이징할 수 있지만, 처음 배울 때는 다소 어렵게 느껴져 진입장벽이 될 수 있을 것 같다.
내가 필요로 하는 부분만 추출해서 가독성을 높이고 좀더 간단하게 활용하려면 어떻게 해야 할까? 아직 파이썬을 자유자재로 쓸만큼 익숙하지는 않은 관계로, 오늘은 이 부분을 정리해보았다.
</br>
1) 단어와 품사만 출력하고자 할 때 아래와 같이 token.form, token.tag로 뽑아낼 수 있다.
result = kiwi.tokenize(text)
for token in result:
print(token.form, token.tag)
카카오 NNP
워크 NNG
를 JKO
효과 NNG
적 XSN
으로 JKB
사용 NNG
하 XSV
려면 EC
다음부터는 결과를 가공해서 활용하기 위해 정리해본 내용들이다.
2) 리스트 형태로 가공하기
word_list = []
result = kiwi.tokenize(text)
for token in result:
word_list.append([token.form, token.tag])
print(word_list)
[['카카오', 'NNP'], ['워크', 'NNG'], ['를', 'JKO'], ['효과', 'NNG'], ['적', 'XSN'], ['으로', 'JKB'], ['사용', 'NNG'], ['하', 'XSV'], ['려면', 'EC']]
3) 리스트 형태로 명사만 추출하기
okt.nouns(text)에 해당하는 코드이다.
word_list = []
result = kiwi.tokenize(text2)
for token in result:
if (token.tag).startswith('N'):
word_list.append([token.form, token.tag])
print(word_list)
결과는 아래와 같이 출력된다.
[['카카오', 'NNP'], ['워크', 'NNG'], ['효과', 'NNG'], ['사용', 'NNG']]
4) Counter로 빈도순 정렬하기 이번에는 Counter를 이용해 빈도를 카운트해 본다. 먼저 리스트 형태로 가공해야 한다.
text = "현재 네이버는 클로바 스마트스피커, 클로바더빙, 클로바노트, 클로바 케어콜 등 다양한 AI 서비스에 음성 AI 기술을 활용하고 있다."
# 클로 / 바 로 잘려서 사용자 사전에 등록
kiwi.add_user_word("클로바", "NNP")
# 명사만 추출하여 리스트로 만들기
words = []
result = kiwi.tokenize(text)
for token in result:
if (token.tag).startswith('N'):
words.append(token.form)
print(words)
> ['네이버', '클로바', '스마트', '스피커', '클로바', '더빙', '클로바', '노트', '클로바', '케어콜', '등', '다양', '서비스', '음성', '기술', '활용']
이렇게 리스트로 만든 뒤, Counter를 이용해 간단히 빈도를 계산할 수 있다.
from collections import Counter
count = Counter(words)
top_nouns = count.most_common(3)
for n in top_nouns:
print(n)
#결과
('클로바', 4)
('네이버', 1)
('스마트', 1)
5) 데이터프레임으로 가공하기 마지막으로, 익숙한 dataframe 형식으로 가공하는 방법이다.
word_list = []
result = kiwi.tokenize(text)
for token in result:
word_list.append([token.form, token.tag])
df = pd.DataFrame(word_list)
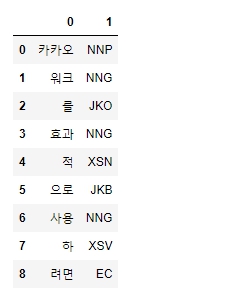
빈 리스트를 만들고 token들을 추가한 뒤, 마지막에 데이터프레임으로 변환했다. Counter를 사용하는 대신 이 결과를 groupby해서 활용해도 되겠다.
마무리하며
- 텍스트 분석 자체도 어려운지라 Kiwi의 공식문서를 처음 봤을 때는 너무 어렵고 복잡하게 느껴져 깊이 들여다보지 못했었다. 하지만 새로운 단어를 추출해내는 기능, 문서 내에서의 위치를 제공하는 부분 등이 매력적으로 느껴저 한번 사용해보기로 했다.
- python을 배우는 여러가지 방법들이 있지만, 막상 문과생이 데이터를 엑셀처럼 자유자재로 사용하려기 위해 필요한 노하우는 따로 있는 것 같다. 그런 것들만 알짜배기를 모아서 하루 익혔으면 좋겠다.
참고 글
- [KIWI] 좋아, 형태소 분석기를 만들어봅시다. https://bab2min.tistory.com/560
Subscribe via RSS